

In questo articolo parliamo dei design pattern usati per lo strato di persistenza dei dati in un database relazionale mediate l’uso di della Java Persistence API (JPA) (JSR 338) e della sua implementazione più matura e popolare che è il framework object relational mapping (ORM) Hibernate.
JPA è da diversi anni largamente usata in molte applicazioni Java siano esse basate su JEE anzichè su Spring ed è quindi naturale che si siano affermate delle best practice, appunto dei design pattern, attorno a questa tecnologia per la creazione di persistence layer efficienti e manutenibili.
Parleremo del perchè sia preferibile usare la composizione anzichè l’ereditarietà, dei pattern Repository e DTO e dell’antipattern Open Session in View che sicuramente molti programmatori, me compreso, abbiamo usato almeno una volta nei nostri programmi.
Partiamo da due pattern strutturali il cui scopo è quello di rendere le applicazioni facili da capire e mantenere che sono appunto la Composizione comparata con l’Ereditarietà e il Pattern Repository.
Indice
Composizione vs Ereditarietà
Si è spesso sentito parlare di quale fosse la migliore soluzione per strutturare le classi Java in un’applicazione ed in particolare se usare l’ereditarietà, quindi avere delle superclassi più generali e delle sottoclassi più specializzate oppure utilizzare la Composizione che come si evince dal nome stesso consente di descrivere una classe in termini di altre classi che la compongono. Senza entrare nel dettaglio sul perchè, che esula dall’argomento di questo articolo e suggerendo di leggere Composizione al posto dell’ereditarietà per chi volesse approfondire l’argomento, la soluzione della Composizione risulta essere nella maggior parte dei casi la soluzione migliore, valida anche nel caso delle Entity JPA come andremo subito a vedere.
Cominciamo col dire che i database relazionali supportano il concetto di composizione, ma non il concetto di ereditarietà. I modelli basati sulla Composizione hanno associazioni di tipo “ha un” modellati come Foreing Key tra una o più tabelle del DB.
Queste associazioni tra tabelle si traducono nel nostro Domain Model in annotazioni di tipo @ManyToMany, @ManyToOne oppure @OneToMany (in base al tipo di relazione) applicati ad attributi di tipo List o Set del tipo dell’entità associate. Vediamo un esempio per chiarire meglio il concetto:
Supponiamo di dover modellare la struttura relativa ad un Autore che pubblica due tipi di pubblicazioni: Libri e Blog Post.
In una struttura che usa l’ereditarietà avremo una cosa del tipo:
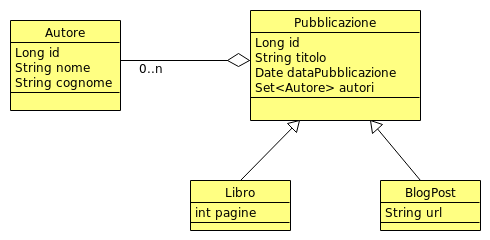
mentre usando la Composizione il domain model diventa:
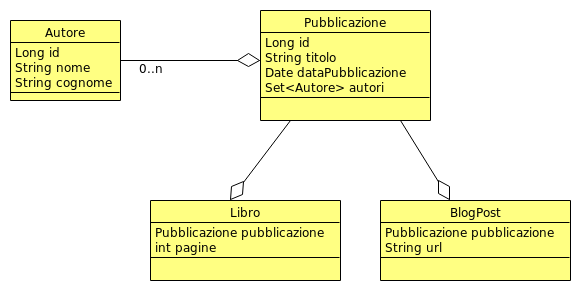
La modellazione come entity, ad esempio della classe Libro, usando la Composizione è la seguente:
@Entity
public class Libro {
private int pagine;
@ManyToOne
@JoinColumn(name = "id")
private Pubblicazione pubblicazione;
...
}
Come possiamo vedere risulta semplice modellare le entities con l’uso della Composizione.
L’ereditarietà, dall’altra parte, modella un’associazione di tipo “è un” ma questo tipo di associazione, come abbiamo già detto, non può essere modellata in un DB relazionale ed per questo che la specifica JPA suggerisce alcune strategie di mapping che consentono di implementare questo tipo di relazione tra le tabelle di un database relazionale.
Le strategie possibili sono le seguenti:
- Mapped Superclass: Questa è la soluzione più semplice per mappare una gerarchia di classi in tabelle di un DB relazionale. Qui ogni sottoclasse viene mappata in una tabella indipendente con la ripetizione in ogni tabella degli attributi (colonne) condivisi, raccolti nella superclasse. Quest’ultima non viene mappata come una entity e non è possibile quindi usare query polimorfiche con le quali sarebbe possibile reperire tutte le entity di uno stesso tipo.
- Table per Class: Questa soluzione è simile alla precedente con la differenza che anche la superclasse è mappata come entity. In questa soluzione è possibile usare query polimorfiche ma la struttura delle tabelle rende la realizzazione delle query polimofiche molto più complessa e quindi è una soluzione che è meglio evitare.
- Joined: Anche con questa strategia si mappa ogni classe della gerarchia ad una tabella del DB con la differenza che anche alla superclasse corrisponde una tabella del DB che contiene solo gli attributi condivisi, mentre le tabelle relative alle sottoclassi contengono solo gli attributi specifici e condividono la chiave primaria con la tabella che rappresenta la superclasse. Qui per reperire i dati delle sottoclassi è necessario mettere in JOIN almeno una tabella, aumentando la complessità delle query.
- Single Table: La strategia a tabella singola associa tutte le entità della struttura di ereditarietà alla stessa tabella di database che contiene quindi tutte le colonne necessarie a mapppare gli attributi di tute le classi della gerarchia. Questo approccio rende le query polimorfiche molto efficienti e offre le migliori prestazioni,
ma ha anche alcuni inconvenienti: Gli attributi di tutte le entità sono mappati sulla stessa tabella del database, ma i record utilizzano solo un sottoinsieme delle colonne disponibili e il resto va impostato a NULL, quindi non è possibile usare i constraint NOT NULL dove magari servirebbe, causando potenziali problemi di integrità.
Come abbiamo visto, la composizione non introduce problemi di mappatura ma tutte le strategie di mappatura dell’eredità hanno i loro trade-off. Quindi, quando modellerai la tua prossima entità, sii consapevoli di questi compromessi e, se possibile, evitarli preferendo la composizione all’ereditarietà.
Repository Pattern
Il pattern Repository è un modello consolidato nelle applicazioni Enterprise. Una classe Repository contiene tutto il codice relativo alla persistenza ma nessuna logica di business. Fornisce metodi per inserire, aggiornare e rimuovere un’entità e metodi che istanziano ed eseguono query specifiche. L‘obiettivo di questo pattern è quello di separare il codice per la persistenza dal codice di business e a migliorare la riusabilità del codice relativo alla persistenza. Rende anche più facile la scrittura e la leggibilità del codice, perché è possibile concentrarsi sulla implementazione dei requisiti anziché sull’interazione con il database.
Se hai usato Spring Data o Apache DeltaSpike, probabilmente hai già familiarità con questo pattern in quanto entrambi i framework ti consentono di generare facilmente classi Repository per le tue entità generando le operazioni più comuni di creazione, lettura, aggiornamento ed eliminazione (CRUD) e query personalizzate basate su interfacce e firme dei metodi.
Consideriamo la seguente entity per rappresentare uno studente iscritto ad una classe:
@Entity
public class Studente {
private Long id;
private String nome;
private String cognome;
private Date dataDiNascita;
......
@ManyToOne
@JoinColumn(name = "id_classe", referencedColumnName = "id")
private Classe classe;
...
}
@Entity
public class Classe {
private Long id;
private int grado;
private String sezione;
...
}
Di seguito uno snippet di codice che definisce un repository estendendo l’interfaccia CrudRepository di Spring Data
che definisce due metodi per caricare l’entità Studente in base al cognome e in base al nome. Questa interfaccia oltre a rendere disponibili le operazioni di base per il CRUD sull’entità Studente, ereditate dall’interfaccia CrudRepository, permette come vediamo di creare altri metodi basandosi sulla notazione. Basta definire dei metodi findBy basandosi sui nomi degli attributi e Spring Data genererà la classe che implementa l’interfaccia definita che realizza le query richieste.
public interface StudenteRepository extends CrudRepository <Studente, Long> {
List<Studente> findByCognome(String cognome);
List<Studente> findByNome(String nome);
}
Open Session in View Antipattern
Aprire una session di Hibernate nel layer di view di una applicazione è un antipattern che è stato usato per anni. L’idea era semplice ed era quella di aprire e chiudere una sessione Hibernate nella view (ad esempio in una JSP) anzichè nello strato di business logic. Facciamo un esempio pratico: Supponiamo di avere una entity Articolo a cui sono associate n entity Commento.
@Entity
@Table(name = "articoli")
public class Articolo {
private Long id;
private String titolo;
private String contenuto;
...
@OneToMany(mappedBy = "articolo", fetch = FetchType.LAZY)
private List<Commento> commenti;
...
}
@Entity
@Table(name = "commenti")
public class Commento {
private String email;
private String testo;
private Date data;
...
@JoinColumn(name = "id_articolo", referencedColumnName = "id")
@ManyToOne
private Articolo articolo;
...
}
Con l’utilizzo di questo pattern quando andiamo a fare il rendering dell’articolo nella view e vogliamo visualizzare i commenti ad esso associati invochiamo direttamente il metodo getCommenti() nella view. Questo si traduce nell’esecuzione di n SELECT che in presenza ad esempio di molti commenti impattano notevolmente sulle performance. Questo è il problema noto come n+1 select issue.
Per evitare questo tipo di problema si usa il pattern DTO, di cui parleremo a breve o mantenendo il controllo della session di Hibernate nello strato di business.
Quest’ultima soluzione richiede che tutte le associazioni richieste, quindi tutti i dati che si vogliono visualizzare nella view, siano inizializzati nello strato di business. Ciò diventa necessario perché il layer di view non ha più accesso alla session di Hibernate e quindi un accesso ad una associazione non inizializzata causerebbe il classico errore
LazyInitializationException, che sicuramente chi ha usato Hibernate ci si è imbattuto almeno una volta.
Quindi, come abbiamo detto, occorre reperire tutti i dati che ci servono nelle nostre classi di business usando le tecniche che JPA e Hibernate ci mettono a disposizione. Vediamo qui le due soluzioni più popolari:
- L’uso delle clausole JOIN FETCH nelle query JPQL
- La definizione di @NamedEntityGraph indipendente dalla query
Utilizzo delle clausole JOIN FETCH
Questa è la soluzione più semplice adatta a praticamente tutti i casi d’uso e può essere utilizzata sia nelle query JPQL (Java Persistence Query Language) che utilizzando la Criteria API. Con questa soluzione il persistence provider, nel nostro caso Hibernate, esegue le query mettendo in JOIN le tabelle collegate e inizializza le associazioni della entity.
Ritornando all’esempio precedente della entity Articolo collegata ad n Commenti, definiamo la seguente query JPQL:
TypedQuery<Articolo> q = em.createQuery( "SELECT a FROM Articolo a LEFT JOIN FETCH a.commenti", Articolo.class);
Quando viene eseguita questa query, Hibernate esegue una SELECT dalla tabella articoli mettendo in JOIN la tabella commenti, tutto in un unica query. In questo modo l’esecuzione della query è molto più veloce che reperire gli n commenti di un articolo eseguendo oltre alla SELECT FROM articoli anche n SELECT FROM commenti, una per ogni commento associato all’articolo.
Inizializzazione delle associazioni con un NamedEntityGraph
Se usi il metodo find dell’ EntityManager per caricare una entity o se stai cercando un modo riutilizzabile per definire il comportamento del recupero di una entity, puoi usare un NamedEntityGraph. Questo meccanismo è stato introdotto con la versione 2.1 di JPA ed è un approccio basato sulle annotation che permette di definire un grafico di entità che verranno recuperate dal database. L’annotazione @NamedEntityGraph deve essere applicata alla entity radice del grafico delle entità.
Vediamo come si utilizza nell’esempio appena visto sopra:
@NamedEntityGraph (
name = "graph.CommentiArticolo",
attributeNodes = @NamedAttributeNode("commenti")
)
@Entity
@Table(name = "articoli")
public class Articolo {
.....
Dopo aver definito il tuo NamedEntityGraph, puoi usare un “suggerimento” per l’esecuzione della query per dire al Persitence Provider di utilizzarlo come un fetchgraph chiamando il metodo EntityManager.find:
Map<String, Object> hints = new HashMap<>();
hints.put("javax.persistence.fetchgraph",em.getEntityGraph("graph.CommentiArticolo"));
Articolo a = em.find(Articolo.class, 1L, hints); // reperisco l'articolo con id=1 e i commenti a questo associati
Questo genererà un’unica SELECT FROM articoli in JOIN con la tabella commenti, uguale a quella vista nel caso precedente.
Data Transfer Object Pattern
DTO è un altro design pattern ben noto e molto utilizzato. Il concetto è quello di introdurre una o più classi per modellare una struttura dati adatta per un caso d’uso specifico al fine di trasferire dati tra gli strati di un’applicazione.
Transfer Object è una semplice classe POJO con metodi getter / setter e non ha nessun comportamento ma funge solamente da contenitore di dati. E’ poi lo strato di business che prelevando i dati dal DB si occupa di popolare questo tipo di classi. Per i client, un DTO è un oggetto in sola lettura, può comunque essere usato per trasferire dati dal client verso il server, nel qual caso il client creerà un proprio oggetto DTO da passare al server per, ad esempio, aggiornare dei dati nel DB.
Riprendiamo l’esempio dell’entity Studente visto sopra e scriviamo uno StudenteDTO che incapsula oltre ai dati dell’entity principale anche i dati relativi alla classe a cui lo studente è iscritto:
package it.esempio.dto
public class StudenteDTO {
private String nome;
private String cognome;
private int classe;
private String sezione;
public Studente(String nome, String cognome, int classe, String sezione) {
this.nome = nome;
this.cognome = cognome;
this.classe = classe;
this.sezione = sezione;
}
public String getNome() {
return nome;
}
public void setNome(String nome) {
this.nome = nome;
}
public String getCognome() {
return cognome;
}
public void setCognome(String cognome) {
this.cognome = cognome;
}
public int getClasse() {
return classe;
}
public void setClasse(int classe) {
this.classe = classe;
}
public String getSezione() {
return sezione;
}
public void setSezione(String sezione) {
this.sezione = sezione;
}
}
Dopo aver definito il DTO, è possibile utilizzarlo come proiezione nelle query JPQL, nelle query native e usando la Criteria API; JPA supporta pienamente l’uso in tutte queste situazioni.
Qui vediamo un esempio di uso in una query JPQL:
TypedQuery<StudenteDTO> q = em.createQuery(
"SELECT new it.esempio.dto.StudenteDTO("
+ "s.nome, s.cognome, s.classe.grado, s.classe.sezione) "
+ "FROM Studente s WHERE s.id = :id", StudenteDTO.class);
q.setParameter("id", 1L);
q.getSingleResult();
Come vediamo si utilizza un’espressione che contiene la parola chiave new seguita dal nome della classe DTO completo di package utilizzandone uno specifico costruttore a cui vengono passati i parametri rappresentati dai dati reperiti dal DB mediante le entity.
Perchè usare DTO
Se si sviluppa lo strato di business e i client in maniera indipendente (ad esempio, un microservizio Java con un’API REST e un front-end JavaScript), l’uso di DTO permette di creare API stabili non soggette ad eventuali cambiamenti di requisiti o ottimizzazioni che avvengono nello strato di business.
Sempre nel constesto di una API REST i DTO consentono di escludere alcuni attributi delle entità, ad esempio attributi ad uso interno che non devono essere visibili a nessun utente, oppure escludere lunghi elenchi di entità associate (relazioni one-to-many o many-to-many) che invece è meglio reperire con specifici endpoint REST ai fini di una maggiore efficienza, selezionando solo i dati utili al tuo caso d’uso.
Svantaggi di DTO
Il principale svantaggio del pattern DTO è l’introduzione di ridondanza dei dati in quei casi in cui il DTO è molto simile se non uguale alla entity. Oltre ad evere due classi praticamente uguali bisogna fare un doppio lavoro quando l’entity dovesse cambiare per qualche motivo.
Inoltre, come insegna l’esperienza, è spesso difficile disaccoppiare le operazioni di CRUD di una API
dal livello di persistenza. Anche se è vero che l’uso di DTO consente di cambiare le tue entità senza cambiare la tua API, i progetti del mondo reale dimostrano che se cambi le tue entità, spesso è necessario modificare anche i DTO. Se ti trovi in una situazione in cui il tuo DTO è identico alla tua entità e sono previsti spesso cambiamenti, dovresti prendere in considerazione la rimozione del DTO ed esporre direttamente l’entità.
Conclusioni
Abbiamo visto alcuni design pattern per lo strato di persistenza e di come molti framework che usano JPA, come ad esempio Spring, li implementano per creare dei modelli di programmazione eleganti ed efficienti. Si è visto anche come la composizione sia preferibile all’uso dell’ereditarietà quando si modellano delle classi che rappresentano dati presenti in database relazionali, il DTO e anche le soluzioni ad un antipattern. Concludo fornendo un un elenco di risorse utili a chi vuole approfondire gli argomenti trattati.
Riferimenti
Java Magazine (Maggio/Giugno 2018)
Bellissimo articolo. Confermo che i DTO sono utilissimi solo se aggregano molti dati aggregati che devono essere recuperati in punti diversi dell’applicazione, e quando il DTO stesso è soggetto a modifiche sporadiche.
Ottimo articolo, chiaro, breve ed efficace. Complimenti.
grazie 🙂
“JPA è da diversi anni largamente usata in molte applicazioni Java siano esse basate su JEE anzichè su Spring”
Grazie per l’articolo ma “anziché” con valore disgiuntivo non si può proprio leggere!
a va bè, opinioni… 😉 Grazie a te