

In questo articolo descriviamo la sempre più popolare architettura a Microservizi che è emersa come la soluzione dominante per lo sviluppo delle moderne grandi applicazioni cloud che hanno la necessità di scalare ed evolversi velocemente. L’idea che sta dietro alla microservices architecture (MA) non è un idea totalmente nuova, ma diciamo che è una evoluzione delle architetture SOA (Service Oriented Application) , una SOA “light” o SOA a “grana fine” (fine-grained), qualcuno l’ha definita, quindi parliamo sempre di architettura orientata ai servizi e distribuita. La cosa che caratterizza maggiormente la MA è la struttura delle applicazioni che sono costituite da un certo numero di servizi indipendenti, ciascuno incentrato su un particolare aspetto del business (quindi servizi “piccoli”, da come suggerisce anche il nome), che comunicano tra loro per realizzare business più complessi.
Indice
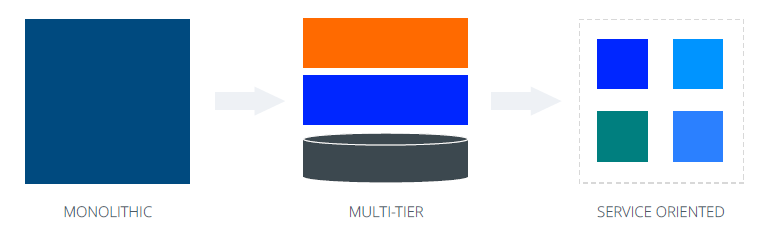
L’evoluzione nello sviluppo delle applicazioni
L’era “monolitica”
In principio, c’era il “monolite”: applicazioni sviluppate e distribuite come una singola entità. Queste applicazioni monolitiche sono facili da implementare, poiché hanno una sola base di codice, tipicamente raccolte in un unico project che vengono distribuite all’interno di un unico pacchetto. Questo tipo di architettura si presta bene per applicazioni piccole o comunque poco soggette a cambiamenti, ma la cosa cambia quando ci troviamo a sviluppare applicazioni complesse e che evolvono rapidamente. In queste situazioni le applicazioni monolitiche possono facilmente diventare mastodontiche in dimensioni e complessità, il che rende difficile muoversi rapidamente in fase di sviluppo, test e implementazione. Un nuovo sviluppatore che entra nel team ha bisogno di imparare il funzionamento dell’intera applicazione, indipendentemente da quello che deve sviluppare, ed ogni piccola modifica deve passare attraverso un test completo dell’intera applicazione prima di essere distribuita in produzione. Inoltre l’unico modo di poter scalare un’applicazione monolitica è quello di replicare l’intera applicazione con conseguente aumento di costi e risorse necessarie. Nella figura sotto un esempio di struttura di una applicazione Java monolitica in cui tutti i servizi dell’applicazione sono impacchettati in un unico archivio (WAR) e distribuiti in blocco.
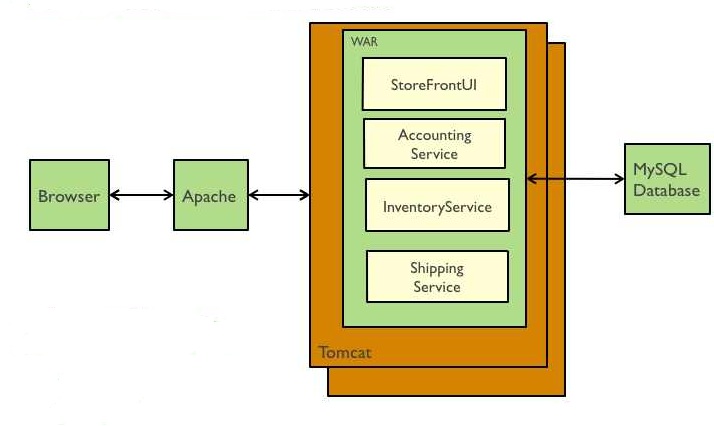
L’evoluzione al multi-tier
scalabilità più efficiente. Questo approccio multi-tier è generalmente costituito da uno strato di dati,
uno strato di logica di business, e un livello di presentazione. Scalare un processo specifico, ad esempio a causa di un aumento del carico, significa scalare solo il livello di logica business.
I database possono essere replicati indipendentemente, mentre lo strato client può rimanere sottile e cross-platform.
Le applicazioni di questo tipo, se diventano troppo grandi, presentano però gli stessi svantaggi dei monoliti con la differenza che tutto il “carico” si sposta nella parte della business logic. Questo modello ha fatto iniziare la tendenza del disaccoppiamento dei componenti; tuttavia, non fornisce sufficienti prestazioni per le applicazioni moderne.
Service Oriented Architecture (SOA)
Il passo successivo che è stato fatto è stato quella di scomporre le applicazioni in base alle funzionalità di business più che una divisione a livello di stack come nel multi-tier. Una applicazione diventa così una sorta di collezione di servizi. Ad esempio, in un’applicazione di ecommerce potremmo avere uno User Service che si occupa della gestione dell’autenticazione, un Order Service per la gestione degli ordini e un Notification Service per la gestione delle notifiche via email. Già con questo tipo di architettura abbiamo i vantaggi in termini di scalabilità e di una maggiore semplicità in quanto abbiamo servizi separati e quindi potenzialmente più piccoli e facili da gestire.
Nonostante questo modello abbia fornito un notevole miglioramento nella costruzione di architetture più efficaci, nella pratica è stata generalmente inefficace a causa di inutili astrazioni e protocolli legacy complessi. Gli sviluppatori si sono trovati ad utilizzare SOA per collegare una vasta gamma di applicazioni che parlavano una lingua diversa, e che hanno richiesto l’implementazione di un ulteriore livello, usato per la comunicazione che è l’ Enterprise Service Bus. Questo porta a configurazioni costose che non possono tenere il passo come la tecnologia e il business di oggi.
La scomposizione delle applicazioni in servizi
Prima di passare ai microservices è utile vedere le varie modalità di scalare un applicazione e capire come da qui si arriva all’architettura a microservizi. Per questo ci viene in aiuto un modello tridimensionale chiamato scale cube:

In questo modello, l’approccio più comune per far scalare un’applicazione è quello replicare eseguendo molteplici copie identiche dell’applicazione dietro un bilanciatore del carico ed è noto come scalatura sull’asse X. Questo è un modo per migliorare la capacità e la disponibilità di un’applicazione.
Similmente alla scale X abbiamo quella lungo l’asse Z dove ciascun server esegue una copia identica del codice con la differenza che ogni server è responsabile per solo un sottoinsieme dei dati. Ci sono in questo caso dei componenti del sistema che sono responsabili dell’instradamento di ogni richiesta al server appropriato. Uno dei criteri di routing di uso comune è un attributo della richiesta, come la chiave principale del soggetto a cui si accede (sharding).
Scalare lungo l’asse Z, come lungo l’asse X, migliora la capacità dell’applicazione e la disponibilità. Tuttavia, questi approcci non risolvono i problemi legati alla crescita delle dimensioni e della complessità dell’applicazione. Per risolvere questi problemi abbiamo bisogno di scalare lungo l’asse Y.
La terza dimensione di questo modello è l’asse Y o asse della decomposizione funzionale, che è l’approccio usato nei microservices. Se scalare lungo l’asse Z vuol dire dividere le cose che sono simili, scalare lungo l’asse Y vuol dire invece dividere le cose che sono diverse. A livello applicativo, scalare lungo l’asse Y vuol dire dividere un’applicazione monolitica in un insieme di servizi. Ogni servizio implementa una serie di funzionalità correlate, come ad esempio la gestione degli ordini, la gestione dei clienti etc.
Decidere come partizionare un sistema in una serie di servizi è un’arte, ma ci sono una serie di strategie che possono aiutare. Un approccio è quello di suddividere i servizi mediante i verbi (azioni da fare) quindi in pratica i vari casi d’uso. Ad esempio, in un ipotetico negozio online partizionato così avremo ad esempio il servizio Checkout, che implementa l’interfaccia utente per il caso d’uso di checkout.
Un altro approccio di partizionamento è di suddividere il sistema in base ai sostantivi o risorse (entità). Questo tipo di servizio è responsabile di tutte le operazioni che operano su entità / risorse di un determinato tipo. Ad esempio, considerando sempre il caso di un negozio online potremmo avere un servizio di Catalogo, che gestisce il catalogo dei prodotti.
Idealmente, ogni servizio dovrebbe avere solo un piccolo insieme di responsabilità, rispondendo al principio di design della singola responsabilità (SRP). L’SRP definisce che una classe dovrebbe avere un solo motivo di cambiare e questo principo ha senso anche a livello di servizio.
Sotto la stessa applicazione java vista prima ma nella sua versione a microservices:
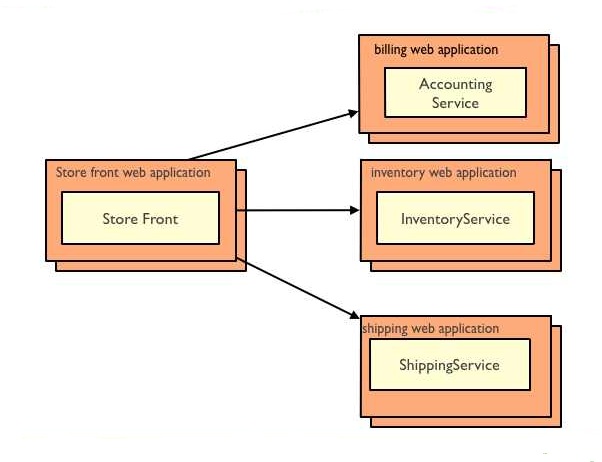
Qui possiamo vedere come ogni singolo servizio sia impacchettato seingolarmente in un archivio WAR e come questi anche il servizio di frontend. In questa versione ciascun archivio WAR viene distribuito in maniera indipendente dagli altri.
SOA vs Microservices
Entrambi gli approcci si basano sulla partizione funzionale anche se SOA tende far interagire n applicazioni, mentre l’approccio a microservizi tende alla realizzazione di una singola applicazione composta da n servizi sviluppati e implementati in maniera indipendente secondo il principio della Singola responsabilità (SRP). Il termine Micro può portare a confusione, in quanto un servizio può essere anche complesso e di una certa dimensione, la cosa invece importante nell’architettura a microservizi è che ogni servizio deve poter essere sviluppato e distribuito in maniera indipendente dagli altri.
Nell’architettura a microservizi la comunicazione tra i servizi è basata su HTTP tramite le API RESTful, passando i dati in formato JSON, spesso attraverso una coda di messaggi, quando è necessario garantire l’affidabilità. I singoli Microservices sono generalmente trattati in modo asincrono, innescati da un evento come una chiamata ad una API o un inserimento di un dato in coda. Questo tipo di comunicazione basata su un protocollo “leggero” quale è l’HTTP è un ulteriore differenza tra microservices e SOA.
Benefici dell’architettura Microservices
La separazione dei componenti sicuramente crea un ambiente più efficace per il build
e il mantenimento di applicazioni altamente scalabili. I servizi si sviluppano e distribuiscono in modo indipendente sono più facili da mantenere, correggere e aggiornare, portando a funzionalità più agili per rispondere ai cambiamenti ambientali odierni. Ma abbiamo altri vantaggi, vediamoli singolarmente:
Eliminazione di singoli punti di guasto
La separazione dei componenti di un’applicazione rende molto meno probabile che un bug o un problema si rifletta sull’intero sistema. Eventuali servizi “difettosi” possono essere isolati singolarmente, riparati e rimessi in funzione senza necessariamente interrompere le funzionalità dell’intera applicazione.
Orchestrazione più “snella”
L’automazione dei processi (build, test , deploy) può essere gestita molto più facilmente avendo servizi “snelli”. Gli ambienti posso più facilmente rimanere coerenti e allineati tra sviluppo, collaudo e produzione e sono in generale necessarie meno configurazioni.
Iterazioni più veloci
Il codice risulta più semplice da capire per gli sviluppatori i quali si possono concentrare su compiti specifici senza impattare sul resto dell’applicazione e senza la necessità di doversi coordinare con gli altri programmatori. Eventuali aggiornamenti riguardano quello specifico servizio e il processo di distribuzione risulta quindi semplificato. Un architettura a microservizi rende fattibile il continuous delivery.
Scalabilità efficace
La scalabilità a livello di servizio individuale diventa più conveniente e può essere fatta “su richiesta” (on demand) in maniera “elastica”. Inoltre, ogni servizio può essere distribuito su hardware che è più adatto alle esigenze specifiche del servizio in termini di risorse. Questo è molto diverso rispetto a quando si utilizza un’architettura monolitica in cui i componenti vengono distribuiti tutti insieme con lo stesso tipo di risorse, tipicamente “abbondanti” per adattarsi a tutte le esigenze del sistema.
Versionamento
Le API possono essere versionati in modo più efficace in quanto i singoli servizi possono seguire il proprio
schema. Major release possono essere fatte a livello di applicazione, mentre i servizi possono essere aggiornati su richiesta.
Flessibilità del linguaggio di sviluppo
l’architettura Microservice elimina ogni impegno a lungo termine sullo stack tecnologico. In linea di principio, quando si sviluppa un nuovo servizio gli sviluppatori sono liberi di scegliere qualsiasi linguaggio di programmazione e framework magari i più adatti per quel servizio. Naturalmente, in molte organizzazioni ha senso limitare le scelte, ma il punto chiave è che non si è vincolati da decisioni prese in passato. Inoltre, poiché i servizi sono di piccole dimensioni, diventa pratico riscrivere usando linguaggi e tecnologie migliori. Significa anche che se un servizio si dovesse riscrivere per un qualche motivo non è necessario “buttare via” l’intera applicazione, diversamente da quando quando si utilizza un’architettura monolitica, dove le scelte tecnologiche iniziali pesano molto e limitano la possibilità di utilizzare diversi linguaggi e strutture per sviluppi futuri.
Svantaggi dell’architettura Microservices
Naturlamente nessuna architettura è esule da svantaggi e in genere ogni architettura applicativa che tenta di risolvere i problemi di scalabilità ha una serie di problemi da affrontare, data la natura complessa dei sistemi distribuiti. Il partizionamento di un’applicazione in servizi indipendenti significa anche che ci sono più parti in movimento da mantenere. Questo chiaramente è abbastanza palese in questo tipo di sistemi ma ci sono di conseguenza nuovi fattori da tenere in considerazione.
Orchestrazione più complessa
Mentre un vantaggio chiave di microservices è la sua capacità di orchestrazione snella, avere più
servizi significa anche mantenere più flussi di distribuzione che vanno mantenuti corretti e coerenti per tutto il ciclo di vita dell’applicazione. Per questo è necessario implementare un alto livello di automazione di tutti i processi.
Comunicazione tra i servizi
I servizi disaccoppiati hanno bisogno di un modo efficace per comunicare senza rallentare
l’intera applicazione. Scambiarsi dati sulla rete introduce latenza e potenziali fallimenti, che possono interferire con l’esperienza dell’utente. Un approccio comune per ovviare a questo tipo di problemi e rendere più affidabili le comunicazioni, è quello di introdurre un coda di messaggi come un ulteriore livello di trasporto.
Coerenza dei dati
Come per una qualsiasi architettura distribuita, garantire la coerenza dei dati è una sfida, sia per lo store dei dati che per i dati in transito sulla rete. Più database replicati e lo scambio costante di dati può facilmente portare a incoerenze, senza l’uso meccanismi adeguati. implementare meccanismi di comunicazione tra processi per i casi d’uso che si estendono su più servizi senza l’utilizzo di transazioni distribuite è difficile.
Manatenere una alta disponibiltà
Garantire un alta disponibilità è un requisito in qualsiasi sistema di produzione. I Microservices
forniscono un’ isolamento e una scalabilità più efficace; tuttavia, il tempo di attività di ogni servizio
contribuisce alla disponibilità complessiva dell’intera applicazione. Ogni servizio deve quindi avere un proprio sistema di misure distribuite per garantire all”applicazione un ampia disponibilità.
Test
Mentre testare un singolo servizio diventa una cosa semplice, non è altrettanto semplice implementare i test di integrazione. Anche qui è necessario automatizzare il più possibile e questo richiede un impegno non indifferente.
Ora che abbiamo esaminato i vantaggi e gli svantaggi diamo un’occhiata ad un paio di questioni fondamentali di progettazione all’interno di un’architettura Microservice, a cominciare dalla configurazione e dai meccanismi di comunicazione all’interno dell’applicazione e tra l’applicazione e i suoi client.
Creare un architettura Microservices
Una cosa da tenere sempre a mente quando si costruisce una architettura microservices è
che il risultato finale è una singola applicazione, sia per come funziona sia per come è
percepita dagli utenti finali. Ciò significa che, ci deve essere una forte coesione tra i servizi, su come vengono mantenuti e distribuiti e questo al fine di preservare la user experience che l’applicazione si è preposta. Vediamo alcuni aspetti importanti da considerare quando ci si appresta a costruire una architettura Microservices
Configurazione
Avere un buon sistema di gestione delle configurazioni, per i test, l’integrazione e il delivery, diventa una cosa importante in questo tipo di sistemi soprattuto in prospettiva di un aumento del numero di servizi. Maggiormente si riesce ad automatizzare maggiore è la probailità di avere prcessi ben testati e correttamente monitorati. Esistono vari sistemi sul mercato per la gestione delle configurazioni e la distribuzione: Chef, Puppet, Ansible, CircleCI, Jenkins, giusto per citarne alcuni, che aiutano nell’implementazione di workflow ottimizzati. Una architettura a microservices ben configurata
consente agli sviluppatori di concentrarsi solo sul proprio codice, massimizzando efficienza e soddisfazione personale.
Meccanismi di comunicazione in una architettura microservices
In un’architettura Microservice, i modelli di comunicazione tra i client e l’applicazione, nonché tra i componenti dell’applicazione, sono diverse da quelle in un’applicazione monolitica. Diamo prima un’occhiata alla questione di come i client dell’applicazione interagiscono con i microservices. Dopo di che vedremo i meccanismi di comunicazione all’interno dell’applicazione.
API Gateway
In una applicazione composta da n servizi potrebbe sembrare naturale che i client chiamino direttamente i servizi che servono per realizzare una determinata funzionalità. Ma questa cosa non sempre risulta essere una buona cosa, in quanto, di norma siamo in presenza di diverse tipologie di client ognuna con le proprie caratteristiche e limitazioni ma anche perchè la logica diventa troppo legata al client. Ad esempio una pagina web di uno store online chiamata da un PC desktop chiamerà sicuramente un numero di serivizi superiore rispetto alla stessa pagina chiamata da un app nativa di un dispositivo mobile. Ecco che si è reso necessario introdurre un’altro componente con lo scopo di gestire le richieste e per fare da router verso i servizi necessari, appunto l’API Gateway.
L’API Gateway espone un interfaccia verso i client e si preoccupa di realizzare la logica in maniera trasparente al client: Un client chiama ad esempio un unico servizio (via internet) e l’API gateway lo realizza chiamando gli n servizi necessari (in rete LAN ad alta velocità) e invia l’output al client. Questo non solo ottimizza la comunicazione tra il client e l’applicazione limitando di fatto il numero di servizi chiamati direttamente dal client (via internet), ma eventuali cambi di implementazione di un servizio o l’aggiunta di uno nuovo può avvenire, anche questa, in maniera trasparente per i client. Sotto una ipotetica struttura di un applicazione di questo tipo:
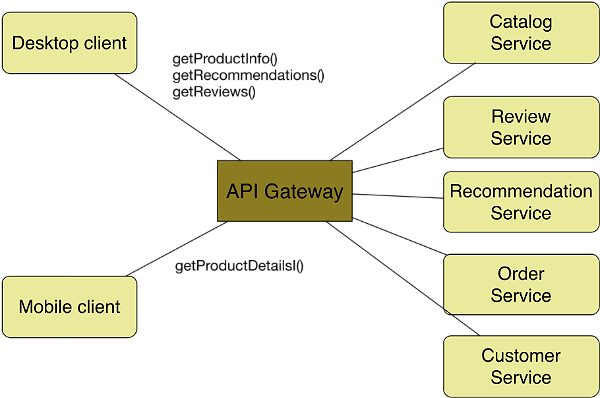
L’API gateway non è considerato di per se un servizio anche se è buona norma che questo componente risulti il più leggero possibile che garantisca una alta disponibilità e che siano scalabile “on demand” in base al carico. Linguaggi di programmazione moderni, come Go o Node.js forniscono dei framework appropriati per costruire API gateway efficienti.
Comunicazione tra servizi
Un’altra importante differenza tra l’architettura Microservice e un applicazione monolitica è il modo come i diversi componenti dell’applicazione interagiscono. In un’applicazione monolitica,i componenti si chiamano l’un l’altro attraverso normali chiamate di metodi. Ma in un’architettura Microservice, i vari servizi vengono eseguiti in diversi processi. Di conseguenza, i servizi devono utilizzare una comunicazione tra processi (IPC) per comunicare. I meccansimi principali di comunicazione tra i sevizi avvengono sempre tramite l’http in maniera sincrona o asincrona, in quest’ultimo caso mediate l’uso di broker di messaggi (AMQP).
Gestione decentralizzata dei dati
Una conseguenza di decomporre l’applicazione in servizi è che il database è anche partizionato. Per garantire un accoppiamento lasco, ogni servizio ha un proprio DB (un proprio schema). Inoltre, servizi diversi possono utilizzare diversi tipi di database venendo a creare la cosiddetta architettura di persistenza poliglotta. Ad esempio, un servizio che ha bisogno di transazioni ACID potrebbe utilizzare un database relazionale, mentre un servizio per gestire un social network potrebbe utilizzare un database NoSQL a grafi.
Refactoring di una applicazione monolitica
Sfortunatamente, non abbiamo sempre il lusso di lavorare su un nuovo progetto e partire quaindi da zero. Anzi, nella maggior parte dei casi facciamo parte di un team di sviluppo che gestisce una enorme applicazione monolitica e che ogni giorno affronta i problemi di cui abbiamo parlato. C’ è però una buona notizia e cioè che ci sono tecniche che è possibile utilizzare per scomporre l’applicazione monolitica in una serie di servizi. Vediamo a grandi linee un possibile approccio.
In primo luogo, smettere di fare il problema peggiore di quello che è realmente, l’ottimismo aiuta sempre. Poi non continuare ad implementare significative nuove funzionalità con l’aggiunta di codice al monolite. Invece, si dovrebbe invece trovare un modo per implementare le nuove funzionalità come servizio autonomo. Questo probabilmente non sarà facile e probabilmente si dovrà scrivere codice disordinato e complesso, che faccia da “colla” tra il servizio e il monolite. Ma comunque è un buon primo passo per trasformare pian piano il monolite.
In secondo luogo, identificare i componenti del monolite che si prestano bene ad essere trasformarsi in un servizio autonomo. Buoni candidati per la scelta sono i componenti che cambiano continuamente, o componenti che potrebbero presentano problemi di conflitti sulle risorse, come ad esempio componenti che fanno cache in memoria o operazioni “pesanti” che fanno largo uso della CPU. Il livello di presentazione (l’interfaccia utente) è anche un altro buon candidato. Quindi trasformare il componente in un servizio e scrivere il codice colla per integrarsi con il resto dell’applicazione. Ancora una volta, questo sarà probabilmente doloroso, ma consente la migrazione incrementale a un’architettura verso i Microservice.
Per chi fosse interessato ad approfondire alcuni casi d’uso reali di grandi aziende che hanno operato un evoluzione da modelli monolitici ad una architettura a microservizi voglio segnalare i seguenti casi: eBay [PDF], Amazon.com, Groupon, e Gilt
Lo stack di una applicazione microservices
Di seguito uno stack completo di una applicazione basata su architettura microservices dove sono evidenziati i vari moduli di cui abbiamo parlato durante l’articolo.
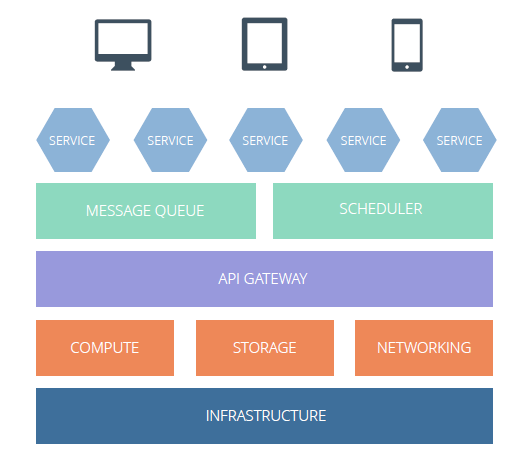
Conclusioni
L’architettura monolitica è un modello comunemente utilizzato per la costruzione di applicazioni enterprise. Funziona ragionevole bene per piccole applicazioni: sia lo sviluppo, i test e la distribuzione di piccole applicazioni monolitiche è relativamente semplice. Tuttavia, per grandi applicazioni complesse, l’architettura monolitica diventa un ostacolo allo sviluppo e la distribuzione. La distribuzione continua (Continuous delivery) è difficile da fare e spesso le scelte tecnologiche iniziali influenzano pesantemente su eventuali nuove implementazioni d evoluzioni dell’applicazione. Per le applicazioni di grandi dimensioni moderne, in cui è richiesta una veloce reattività ai cambiamenti e quindi un accelerazione di tutti processi è più sensato utilizzare un’architettura Microservice che decompone l’applicazione in una serie di servizi, e che rende l’intera applicazione di più facile sviluppo, test, manutenzione e distribuzione.
Articolo chiaro e ben fatto 🙂
Dietro c’è un mondo e l’argomento modularità e moduli che offrono servizi non è nuovo ma vecchio di anni, basti pensare in primis al Kernel (modulare) di Linux fino al framework OSGi, quest’ultimo abilitante ai microservizi e nato circa 15 anni fa. Una nota. Nella tua rappresentazione dello “stack di una applicazione microservices”, non mi torna l’ordine. Adottando l’API Gateway i servizi non sono esposti direttamenti ai consumatori, come hai tra l’altro spiegato in uno dei paragrafi precedenti.
Hai acquistato un lettore!
Ciao, Si, quella figura rappresenta i moduli coinvolti, nella pratica è come hai detto, in presenza di gateway i servizi sono esposti tramite quest’ultimo. Grazie 🙂
Bella lettura, e grazie anche al commento di Musarra che ha posto la stessa domanda che volevo farti.
A mio parere le difficoltá maggiori che incontra il mondo dei Microserivces altro non é che l’insieme degli stessi problemi che da sempre si devono affrontare in ambito enterprise.
La buona notizia potrebbe essere che quando si va sulla strada giusta ogni problema diventa sempre un pochino piú semplice.
Bellaaa
Da un neofita, complimenti per l’articolo. Volevo chiederti se conosci qualche libro che tratti gli argomenti sopra esposti. Il tema dell’evoluzione delle applicazioni mi affascina e mi servirebbe per comprendere a pieno il tema. Grazie ancora per l’articolo.
Un bellissimo articolo che fa una panoramica sulla complessità dell’architettura a micorservices che a mio giudizio funziona pienamente sulla carta e in un mondo perfetto, spostando la complessità e i costi sull’infrastruttura sistematica (Cloud , Kubernetes, Dockers e altri software vari)
“Tuttavia, per grandi applicazioni complesse, l’architettura monolitica diventa un ostacolo allo sviluppo e la distribuzione.”
Io risponderei “MA ANCHE NO!” dipende da cosa si intende per “applicazione complessa” !
Complessa “Funzionalmente” ?
Complessa dal punto di vista del carico di lavoro ?
Un applicazione bancaria MONOLITICA con 150 tabelle e più di 70 funzionalità e’ abbastanza complessa ?
Riportarla a microservices seguendo il principio del Singola responsabilità e’ stato impossibile ed e’ proprio questo il caso in cui io sono più propenso a dire che queste architetture funzionano solo su piccoli progetti in cui ti puoi permettere di avere Services completamente disaccoppiati.
Un’altro che la pensa come me :
https://www.html.it/23/01/2018/architetture-microservice-non-solo-vantaggi/
Ciao!
Bell’articolo, grazie.
Volendo rispondere a Christian: si possono avere architetture a microservizi efficaci anche per applicazioni “mastodontiche”; allo stesso tempo, per applicazioni che devono fare una sola cosa per sempre, senza alcuna necessità di evolvere nel tempo, un’architettura a microservizi può non essere necessaria.
Qui alcuni spunti:
https://www.slideshare.net/GiulioRoggero/favorire-i-feature-teams-con-architetture-microservices
Noi ci occupiamo dello sviluppo di piattaforme a microservizi e API anche per grandi clienti (es. mondo bancario e assicurativo); aggiungerei che oggi, senza un’architettura a microservizi, non riuscirebbero a stare dietro al mercato neanche assumendo il doppio degli sviluppatori.
L’articolo mi è piaciuto molto. Mi piacerebbe approfondire i vari aspetti. Unica critica però è che l’articolo presenta veramente troppi errori di ortografia facilmente evidenziabili con qualsiasi word processor.
Grazie dell’apprezzamento e della segnalazione di errori ortografici… che ho prontamente corretto…. 😉
Sto studiando per realizzare una web applicationche usi Angular come front end e Microservizi per la parte back end utilizzando docker e kubernetes. Ho appena finito di realizzare il primo microservizio e devo interfacciarlo con il front end. Vorrei sapere, dato che angular utilizza la porta 4200 e il microservizio la porta 5051, vorrei sapere come poter riuscire a superare il problema del CORS (per poter utilizzare dati da un dominio diverso da quello in uso)
Sto usando java come linguaggio e Visual Studio Code come ide della parte front end e Spring Tool Suite per la parte back end.
Grazie
Ciao. Le seguenti risorse dovrebbero fare al tuo caso: https://italiancoders.it/cors-in-dettaglio/ – https://spring.io/guides/gs/rest-service-cors/
https://medium.com/@valeriocomo/angular-api-proxy-4ce138c6ca50
Ciao Giuseppe. Eccomi nuovamente a distanza di qualche anno. Recentemente ho pubblicato l’articolo Cosa sono gli OSGi Remote µServices (https://bit.ly/3hUNqhY), che tratta come il framework OSGi può essere benissimo incastonato nel panorama del classico stile architetturale dei Microservices che i più conoscono. Mi farebbe piacere ricevere un tuo feedback sull’articolo. Grazie.
Ciao Antonio
ottimo articolo, completo di tutto, sicuramente una risorsa che consiglierei per chi ha interesse verso il framework OSGI. Complimenti
Articolo molto chiaro. Complimenti.
Ho voluto raggruppare secondo me quali sono i pro dei microservizi:
-possono essere scritti con diversi linguaggi, puoi quindi creare dei progetti Java o con altri linguaggi noti;
-per un microservizio basta un piccolo team di persone;
-il microservizio può essere creato in modo indipendente dagli sviluppatori;
-la creazione è molto più rapida rispetto ai sistemi tradizionali e questo rende più rapida anche la distribuzione;
-è più semplice isolare un eventuale bug e risolverlo;
-ogni modifica interviene solo sul singolo microservizio interessato, senza dover toccare il resto della struttura;
-l’architettura dei microservizi è scalabile e cresce con il crescere dell’azienda.
Mentre i contro possono essere:
-gestione di un sistema più complesso;
-se un’applicazione è molto elaborata, il numero dei microservizi può essere alto e di conseguenza diventa complessa l’intera gestione;
-deve sempre essere aperto e attivo un servizio di comunicazione;
-i test dei microservizi in fase di distribuzione possono diventare anche molto lunghi;
-gli sforzi rischiano di essere maggiori rispetto ai metodi tradizionali perché stiamo parlando di un sistema distribuito.
Roberto di Nextre Engineering